My Apollo window has frozen. What do I do?
Try reloading your browser window.
- For Chrome: Shift Command R
- For Firefox: Ctrl+R
- For Safari: shift+reload
Some data tracks are very slow to load.
The way JBrowse works within Apollo, the first time your load up a track it might take a while. But once loaded, any successive loads will be quicker.
I used to see tracks and now they are gone.
Close the track and open it again. Yes, this is the standard 'turn it off and turn it on again' solution.
What is the meaning of the lower case letters in the nucleotide sequence?
These indicate regions of low complexity. They have no impact/implication with respect to annotation.

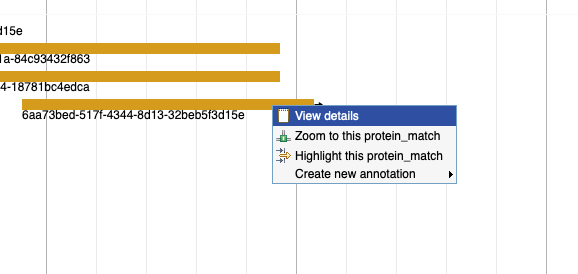
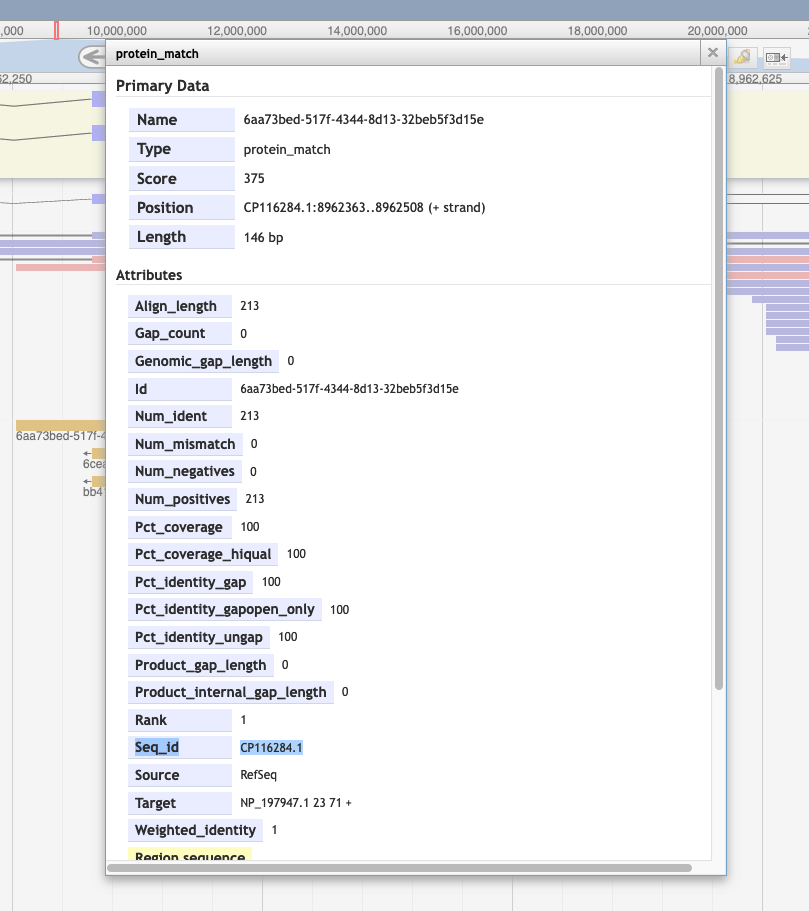
Is it possible to know which organism is the source for a particular protein alignment (in the Protein Alignment track)?
By right clicking on the alignment, and then selecting 'View details.' You'll see the GenBank accession in the id section and can search for that at NCBI.
Where is the track metadata?



TRACK NAME | Description of data |
Col-CC_Genomic_Annotations_Data | Result of NCBI Eukaryotic Annotation Pipeline |
AT-Col-CC-Liftoff-from-TAIR10.1 | v11 models mapped to v12 reference using Liftoff |
| TranscriptomeReconstructoR models | Method: (1) Assembled expression evidence: ONT-DRS (ERR3764345 - ERR3764351), CAGE-Seq (SRR10045003 - SRR10045005), PAT-Seq (SRR7160296, SRR7160297, SRR7160299), plaNET-Seq (SRR9117170 - SRR9117173) (2) Aligned all the datasets to Col-CC genome (3) Built TRR based annotation using alignment (bam) files Output:
|
Gnomon Models | One of the outputs of the annotation pipeline. These are a superset of the final set of annotated models. "Gnomon annotation of the genomic sequence. Sequence identifiers are provided as accession.version for the genomic sequences and Gnomon identifiers for the Gnomon models:gene.XXX for genes, GNOMON.XXX.m for transcripts and GNOMON.XXX.p for proteins. These identifiers are NOT universally unique. They are unique per annotation release only." (from NCBI documentation) |
| Protein Evidence | |
| Protein alignments | Alignments of Arabidopsis thaliana and other Brassicaceae proteins, including Araport 11 annotated proteins, to the genomic sequence(s). These alignments may have been used as evidence for gene prediction by the NCBI annotation pipeline. |
| PFAM domains | Results from an INTERPROSCAN run on the proteins from the V12 prediction to get the PFAM domain information, converted to absolute position on the Col-CC assembly. |
| PFAM domains - Liftoff | Results from an INTERPROSCAN run on the proteins from the Araport11 release to get the PFAM domain information, converted to absolute position on the Col-CC assembly (using the Liftoff file that converted Araport11 coordinates to Col-CC coordinates). |
| PANTHER families | Results from an INTERPROSCAN run on the proteins from the V12 prediction to get the PANTHER family information, converted to absolute position on the Col-CC assembly. |
| PANTHER families - Liftoff | Results from an INTERPROSCAN run on the proteins from the Araport11 release to get the PANTHER family information, converted to absolute position on the Col-CC assembly (using the Liftoff file that converted Araport11 coordinates to Col-CC coordinates). |
| Transcript Evidence | |
| Known Reference Sequences | "Alignments of the annotated Known RefSeq transcripts (identified with accessions prefixed with NM_ and NR_) to the genome." (from NCBI documentation) These were NOT used in generating the Col-CC annotation. They are alignments of the annotated transcripts to the genome and can provide additional insight into the predicted gene structures independent of the prediction. |
| Model Reference Sequences | "Alignments of the annotated Model RefSeq transcripts (identified with accessions prefixed with XM_ and XR_) to the genome." (from NCBI documentation) These were NOT used in generating the Col-CC annotation. They are alignments of the annotated transcripts to the genome and can provide additional insight into the predicted gene structures independent of the prediction. |
| Col-CC Same Species | Alignments of same-species cDNAs, ESTs and TSAs to the genomic sequence(s). cDNAs and ESTs alignments (not TSAs) may have used as evidence for gene prediction by the NCBI annotation pipeline. The TSA alignment track is a subset of the Col-CC Same Species track. |
| TSA alignment | Alignments of transcripts assembled from RNA-Seq reads, and submitted to GenBank (see accessions DAHAIV01, GGJX01, GJRK01 and GKIF01). These were not used as evidence for gene prediction by the NCBI annotation pipeline. |
| RNA seq tracks | Some tracks are already present. Name is based on the GenBank record, for example, SRR1019221. You can link to that record using this base URL for more information on the experiment: https://www.ncbi.nlm.nih.gov/sra/SRR1019221 (more coming) |
| Long Read alignments | Alignments of individual IsoSeq reads in SRA. These alignments may have been used as evidence for gene prediction by the NCBI annotation pipeline. Right clicking on the read itself will allow you to ‘View Details’ and see the ID of the SRA entry for the experiment. Using the id (e.g., SRR11031292), you can go to the full GenBank record for the experiment. https://www.ncbi.nlm.nih.gov/sra/?term=SRR11031292. |
What does the warning symbol mean?
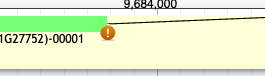
This symbol means that the location and sequence of the splice site needs to be investigated and verified because it does not conform to the GT-AG rule.
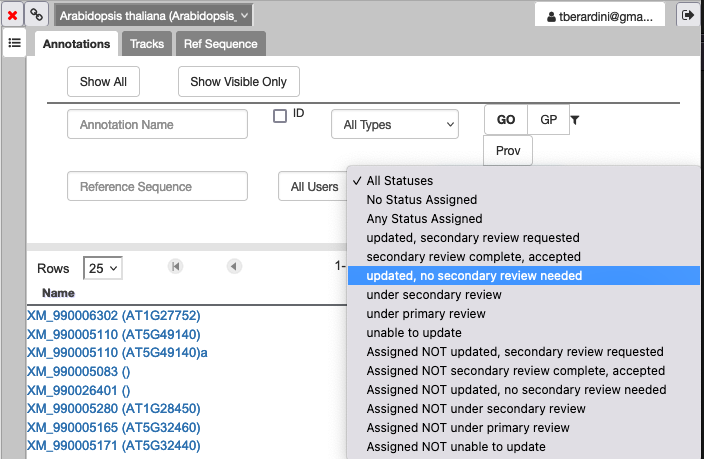
How do I see genes that need secondary review?
In the Annotations tab of your right hand panel, click on the dropdown for "All Statuses" and select the status you want to filter the annotations to review.
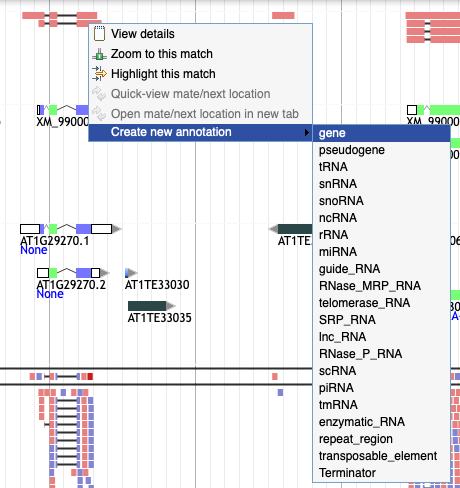
I want to drag an element from an evidence track to the user-created annotation track but I can't!
Right click on the element and select 'Create new annotation' from the menu. Pick the type of element you want to create and it will appear in the yellow track.
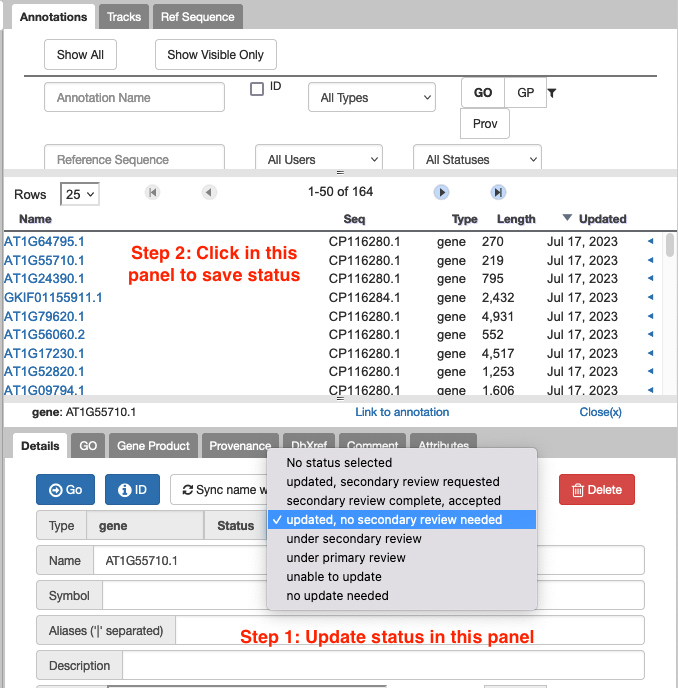
The comment or status I typed in hasn't saved. How do I make sure it saves?
For saving comments and gene status, make sure you click outside of the panel where you created the comment to ‘make it stick’.